1、乱序排序
如下图,希望对A列的应聘人员随机安排面试顺序。
先将标题复制到右侧的空白单元格内,然后在第一个标题下方输入公式:
=SORTBY(A2:B11,RANDARRAY(10),1)
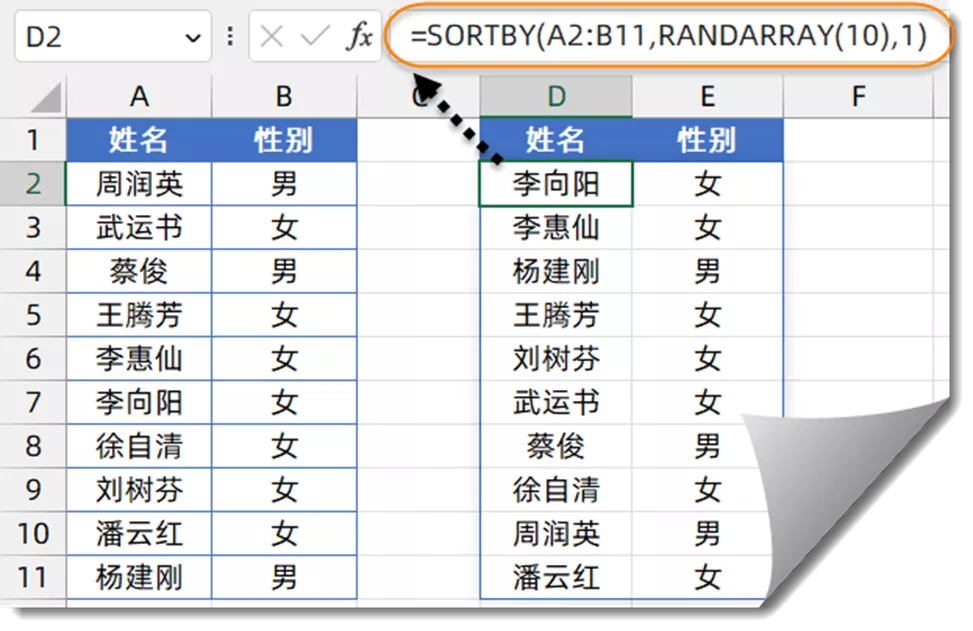
RANDARRAY的作用是生成随机数数组,本例公式使用RANDARRAY(10),表示生成10个随机数的数组。
SORTBY函数的排序区域为A2:B11单元格中的数据,排序依据是按随机数数组升序排序。因为公式每次刷新所生成的随机数数组是不确定的,所以A2:B11单元格中的数据也会得到随机的排序效果。
2、在不连续区域提取不重复值
如下图所示,希望从左侧值班表中提取出不重复的员工名单。
其中A列和C列为姓名,B列和D列为值班电话。
F2单元格输入以下公式:
=UNIQUE(VSTACK(A2:A9,C2:C9))
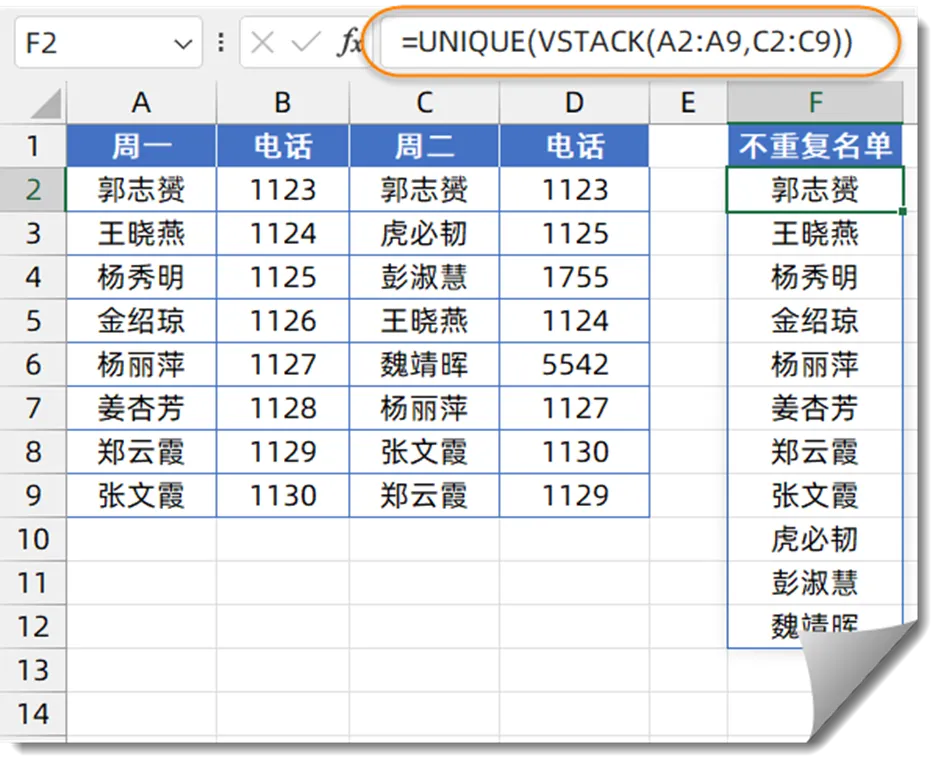
先使用VSTACK函数,把A2:A9和C2:C9两个不相邻的区域合并为一列,然后使用UNIQUE提取出不重复的记录。
3、判断所在部门
如下图所示,B列是一些带有部门名称的混合字符串,希望根据E列的对照表,从B列内容中提取出部门名称。
=INDEX(E$2:E$6,MATCH(1,COUNTIF(B2,”*”&E$2:E$6&”*”),))
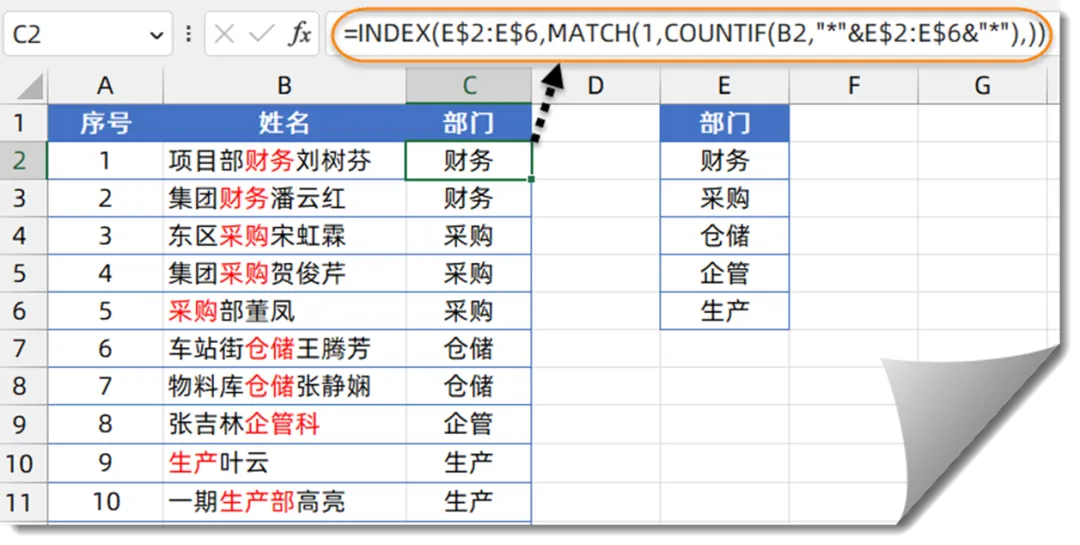
COUNTIF第一参数为B2单元格,统计条件为”*”&E$2:E$6&”*”,统计条件中的星号表示通配符,也就是在B2单元格中,分别统计包含E$2:E$6部门名称的个数,结果为:
{1;0;0;0;0}
再使用MATCH函数在以上内存数组中查找1的位置。
最后使用INDEX函数,在E$2:E$6单元格区域中,根据MATCH函数的位置信息,返回对应位置的内容。
4、提取末级科目名称
如下图所示,希望提取B列混合内容中的班级信息,也就是第三个斜杠后的内容。
C2输入以下公式,向下复制到B9单元格。
=TEXTAFTER(B2,”\”,3)
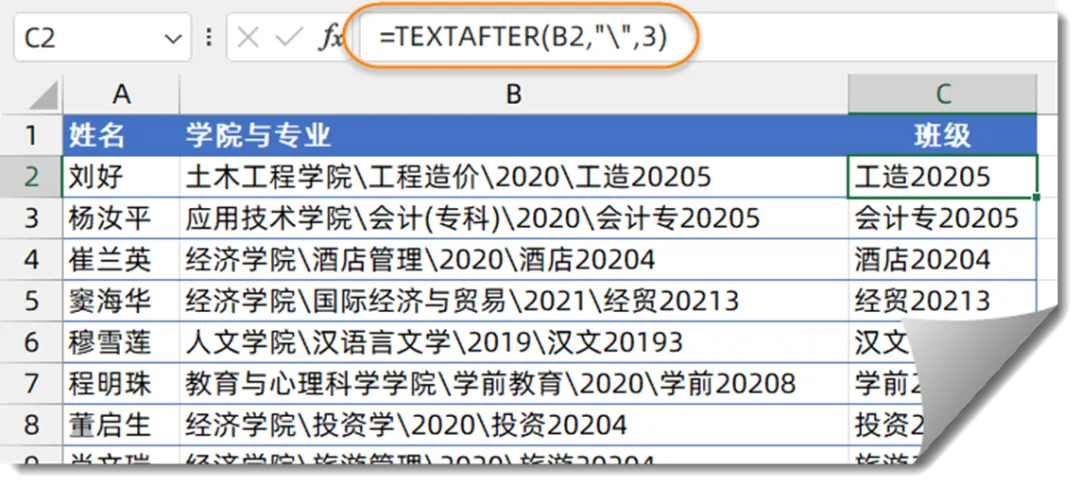
TEXTAFTER函数用于提取指定字符后的字符串,第一参数是要处理的字符,第二参数是间隔符号,第三参数指定提取第几个间隔符号后的内容。
5、数据转置
如下图所示,需要将A列中的姓名,转换为多行多列。
D6单元格输入以下公式,按回车:
=INDEX(A:A,SEQUENCE(E3,E4,2))&””
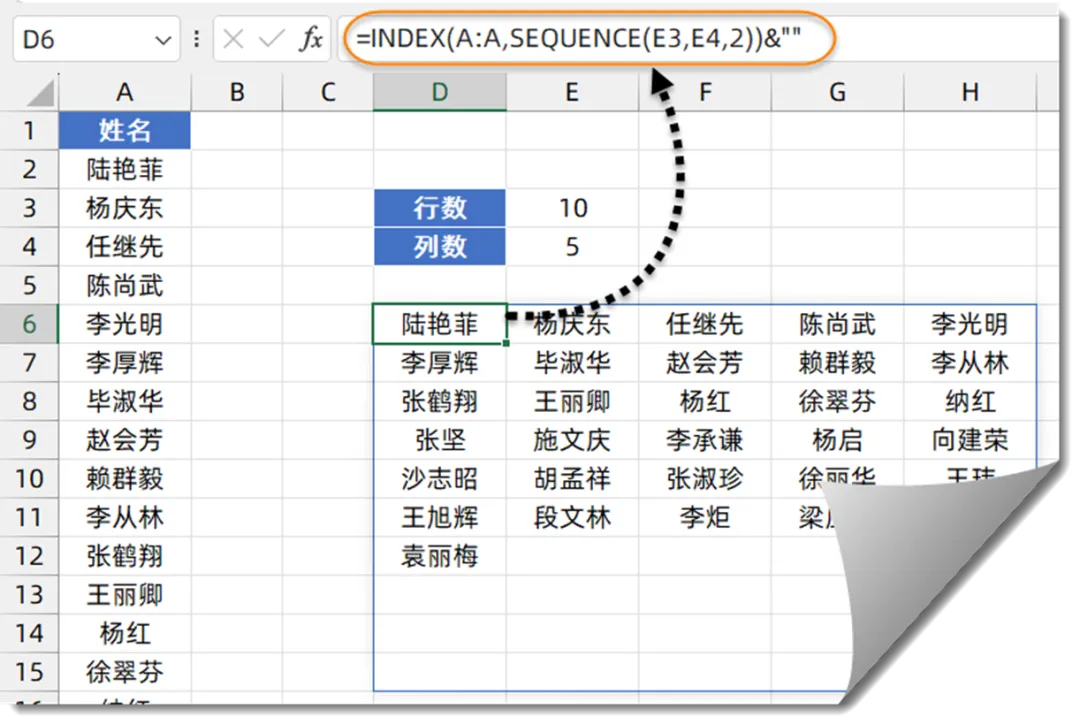
SEQUENCE函数的作用是按指定的行列数生成序号。
公式中的“SEQUENCE(E3,E4,2)”部分,用SEQUENCE函数根据E3和E4单元格中指定的行列数,得到一个从2开始的多行多列的序号。
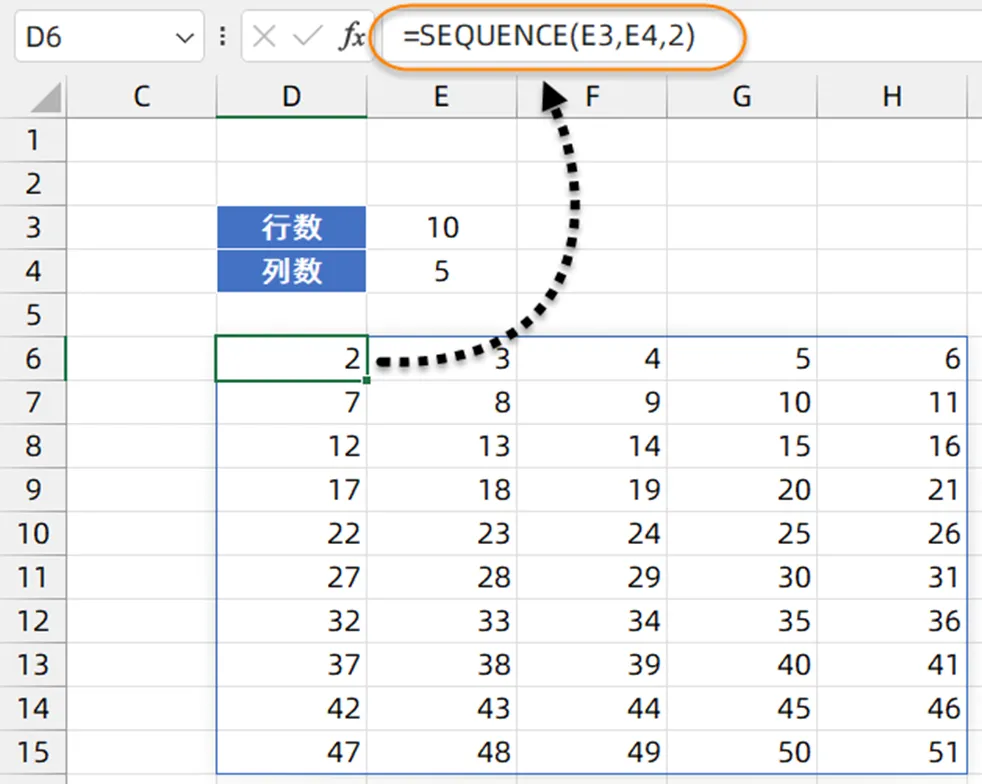
最后用INDEX函数,以SEQUENCE函数得到的序号为索引值,返回A列对应位置的内容。
当INDEX函数引用了空白单元格时会返回一个无意义的0,公式最后加上&“”, 就能够屏蔽这个无意义的0值。
最新评论
下载地址呢
没有下载?
这篇文章写得深入浅出,让我这个小白也看懂了!
这个确实很实用,工作中会经常遇到这个问题。
这个教程还是比较实用的,希望可以对大家有点用。